NVIDIA GH200
584 upstream tests and 235 package tests passed.
Product PTX Kernel Factory
Private beta / NVIDIA GPUs
GPU kernels that improve with every run.
A fully autonomous agent swarm explores implementations, tests them on target NVIDIA hardware, and carries what it learns into the next generation.
01 Compounding system
Each run expands the evidence available to the swarm. Over time, the search becomes more informed, the strategies become more effective, and the resulting kernels become stronger.
Specialized agents search different implementation paths at the same time.
Candidates are compiled, checked, and benchmarked on the target hardware.
Useful results become experience for the next search, not a discarded trace.
02 Inside SwarmOS
SwarmOS exposes every level of a run, from the global control plane to one agent's reasoning, plan, and workspace.
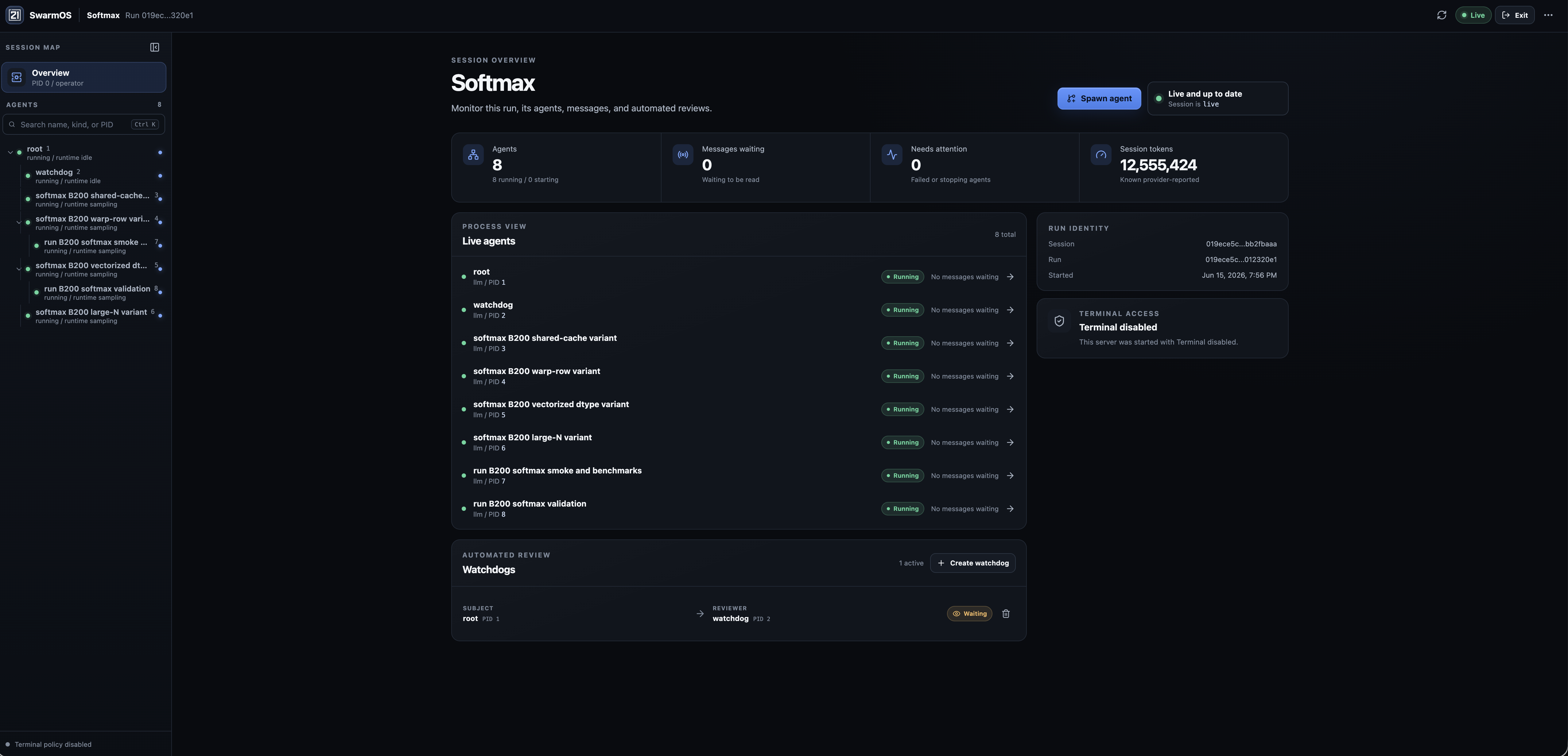
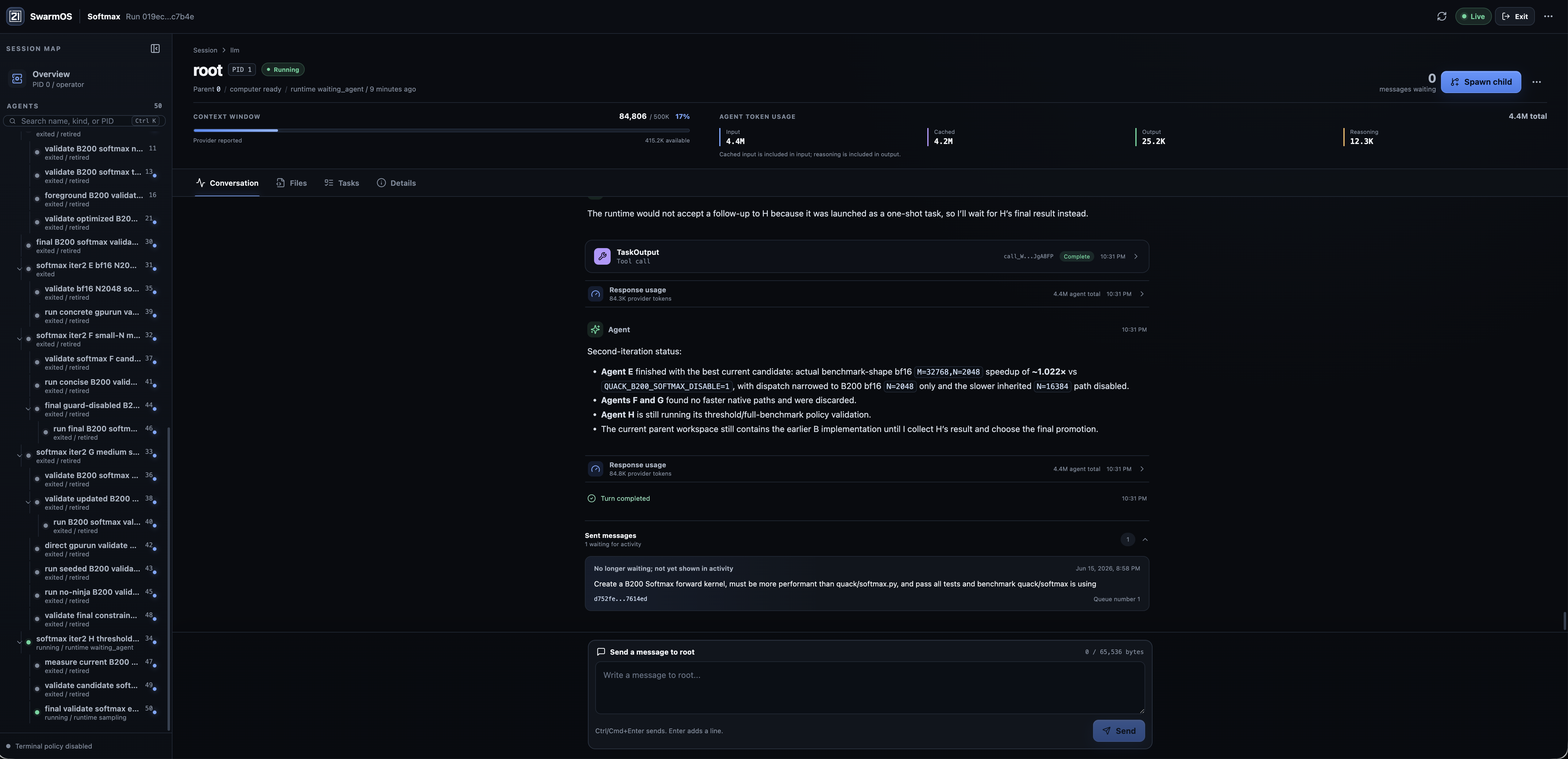
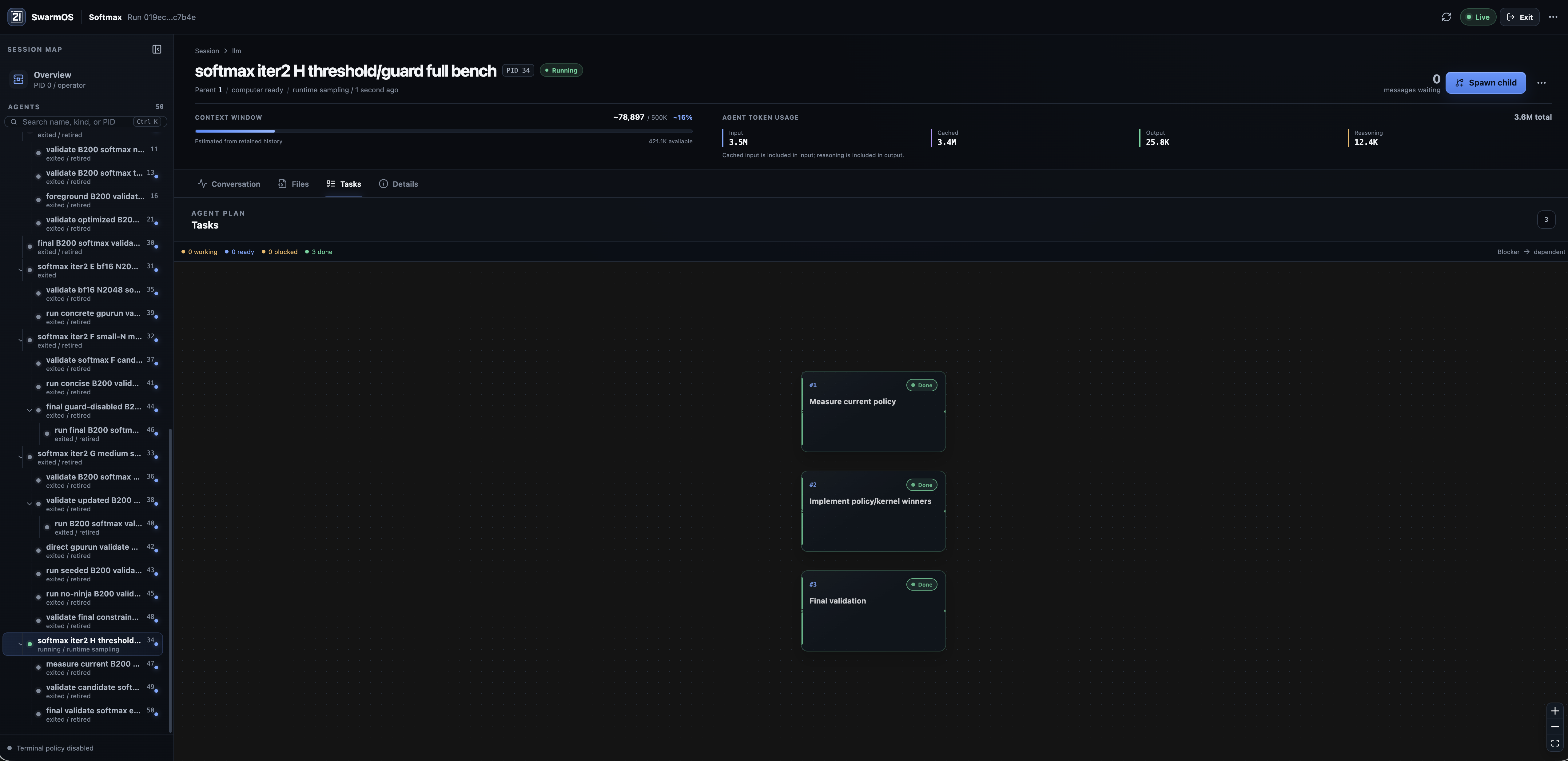
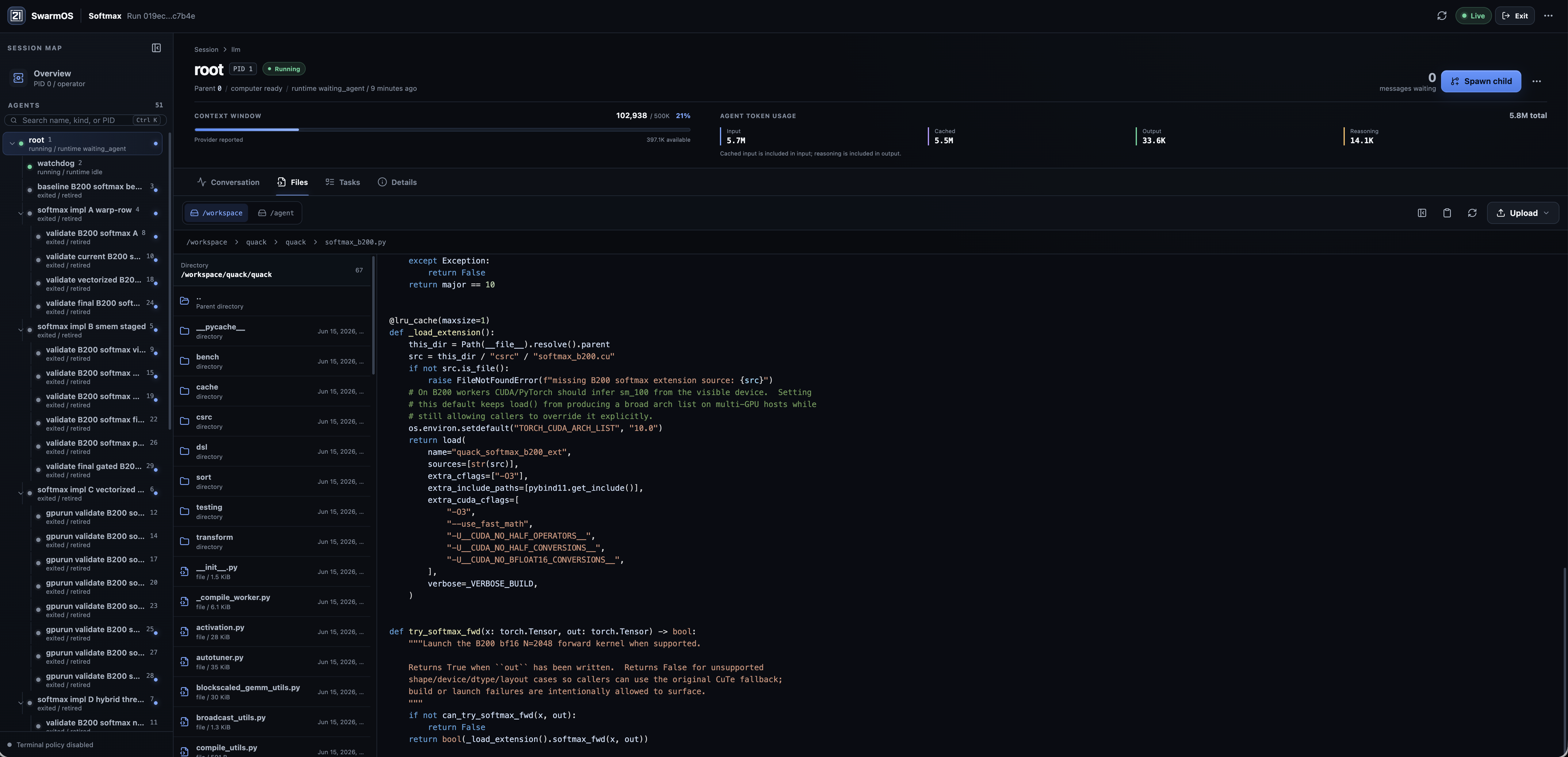
03 Open-source proof
The first four factory artifacts cover RMSNorm and Kimi Delta Attention across Hopper and Blackwell. Source, tests, benchmark methods, and reports are open for inspection.
584 upstream tests and 235 package tests passed.
All 580 upstream tests passed.
48 package tests and 65 subtests passed.
Faster in every comparable case; all 66 package tests passed.
Operator-level results do not imply the same full-model speedup. The launch article includes test coverage, limitations, and measurement context.
04 Beta access
Starter and Pro include subscription access plus discounted spot GPU access. Tokens and cloud compute are billed as used.
$200 / month
$2,000 / month
Contact us
Start with an operation that is too slow, a new architecture without a mature kernel, or an important workload that has not justified weeks of specialist time.
Request beta access